Link
Highlights&&Note
建思路,将整体实践方法论进行拆解。
^54df8fcd
Content
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
限制个人潜能的从来不是某套工具,而是思维模式。——《打造第二大脑》
建思路,将整体实践方法论进行拆解。
^54df8fcd
Matrix 首页推荐
Matrix 是少数派的写作社区,我们主张分享真实的产品体验,有实用价值的经验与思考。我们会不定期挑选 Matrix 最优质的文章,展示来自用户的最真实的体验和观点。
文章代表作者个人观点,少数派仅对标题和排版略作修改。
限制个人潜能的从来不是某套工具,而是思维模式。——《打造第二大脑》
流畅记忆的价值并不仅仅在于记住一些事实。许多实验并非用鹦鹉学舌式的记忆问题来测试学生,而是要求他们进行推理,绘制概念图[4],或回答开放式的问题。在这些研究中,记忆力的提高能够转化为一般理解能力,及解决问题能力的提高。
好的卡片不是死记硬背,而是要求去推理,绘制概念图,或回答开放式提取(Retrieval)是 SRS 有别于传统学习模式的关键。仅仅简单回顾材料(如多读几遍)既没有加强记忆,更不能增进问题解决能力,而「提取」往往可以。这种通过「提取以掌握」的现象也被称为「测试效应」,因为往往发生在做自我测试时,故此得名。它形似学校考试,目的上又有所相反:「提取练习」是为了从测试中进行学习,而非「评估」学习成果。
提取或者说是测试,目的是进行学习,而不是评估学习的成果卡片的焦点应明确(Focused):细节太多的问答不会让你专注,回答时的「提取效应」无法完整地刺激记忆、点亮全部的「思维灯泡」。不够聚焦的问题,还让你更难判断回答是否全面、差异在哪里。因此,最佳做法一般是:一次问答只聚焦一个细节。
尽量聚焦少的细节,太多的细节会让我不够专注地回忆,无法点亮所有的思维灯泡卡面应能诱导出一致的回答(Consistent),让每次任务都点亮相同的「思维灯泡」:否则,你可能遭遇「提取引发遗忘」(retrieval-induced forgetting)[7]—— 这是一种干扰现象,即已记住的会更牢,没记住的更易遗忘。(后文将讨论一种新的卡片,每次重复时都要求一个新答案,但它产生改变的效应不是「提取练习」)
同个任务只能点亮相同的思维灯泡.也就是说,同一个卡片,不会让你回忆出不同的答案卡片应让提取费工夫(effortful):卡片练习的重点,是让你从记忆中提取答案, 而不应让你简单地从卡面「推测」答案(此外,「线索」很重要,我们稍后讨论)。实际上,提取练习的努力程度与效果正相关。这点正是强调复习和复习之间要有间隔的动机之一:如果回忆答案太容易,那提取练习效果不大[9]。
提取难度与效果正相关.但过难会降低积极性.
要有适当的提示,不能太简单也不能太难我们会穷尽式地处理这份阅读材料,以最详尽地展示这些通用的制卡原则。请注意,实践中你通常不会也不必这么系统地学习。你一般只会关注文章中你认为最有价值的部分,然后在非常有必要的时候跳回原始材料,寻找与你理解最相关的信息并做成卡片 —— 这值得一赞!完美主义会过度消耗你的动力,穷尽式处理只是表面正确,实际上是浪费你的注意力,它们本应该放到更有价值的地方。这类问题会在后面更深入地讨论。
穷尽式地处理并不是很好的选择.战术上努力,战略上懒惰.在必要时跳回原始材料就行我们假如直接这么写卡:「制作鸡肉高汤需要什么?」,那么在回答的时候因为数量或者原料名称未作要求,所以很难作答。这样的卡片不够准确,也不够聚焦 :同时要求提取的细节太多,所以想要加强的记忆不会全部被强力激活;并且因为它要的答案太多,因此的一致性、可控性也不好:每次回答,你会记起一些,又忘掉另一些。因此激活不够一致,容易导致记忆受到侵蚀。
像我写的高数卡片…在谈及事实时,我们自然会想添加一些解释。我个人会在细节不容易想到,或者事实背后的解释比较有意思的时候,添加一张「解释卡」
对有趣事实进行解释是很有意思的事情问:为什么我们做鸡肉高汤要用骨头?
答:它们富含明胶(吉利丁,gelatin),可以产生浓郁的口感。
*很好的解释卡,但仍有不足,像骨头比较便宜这个答案也是有可能出现的.这样就显得一致性,可控性不够好.还有改进空间
问:骨头如何产生鸡肉高汤的浓郁口感?
答:它们富含吉利丁。
更好,排除了骨头便宜的干扰,更加精准*
解释卡能强化「事实性」提问中的知识,而「解释」本身也让事实富有意义—— 这点也许更重要。此类卡片像钩子一样,将烹饪生涯中的想法与学到的「事实」相互关联起来。比如你学完这张卡的第二天,如果正好吃到「果冻鸡爪」,就可能考虑拿鸡爪作高汤材料(因为这是鸡身上明胶最丰富的部分),因为今天这张卡让你知道明胶能提升口感。
通过解释,将解释卡与事实卡联系起来.问:鸡肉高汤中使用的典型香料是什么?
答:洋葱、胡萝卜、芹菜、大蒜和香菜
但是,除非你有一定经验,否则这个卡片对你来说可能并不可控,或是每次记的原料不一致。这样的无序列表要转化为好卡片,颇具难度。
对此,一个好策略是创建一组问题,并对选项分别挖空,并要求你逐一填空(下面用???指挖的孔):
问:典型的鸡肉高汤香料:
- ???
- 胡萝卜
- 芹菜
- 大蒜
- 香菜答:洋葱
问:典型的鸡肉高汤香料:
- 洋葱
- ???
- 芹菜
- 大蒜
- 香菜答:胡萝卜
…以此类推。这里注意到选项列表顺序没有变动,这样你在重复回忆时,最终一定程度上会形成视觉形状上的记忆。
cloze形式的anki卡片在这里就很实用,一次仅仅聚焦一个思维灯泡,并且形成视觉上的记忆
Faster RCNN使用CNN提取图像特征,然后使用region proposal network(RPN)去提取出ROI,然后使用ROI pooling将这些ROI全部变成固定尺寸,再喂给全连接层进行Bounding box回归和分类预测。
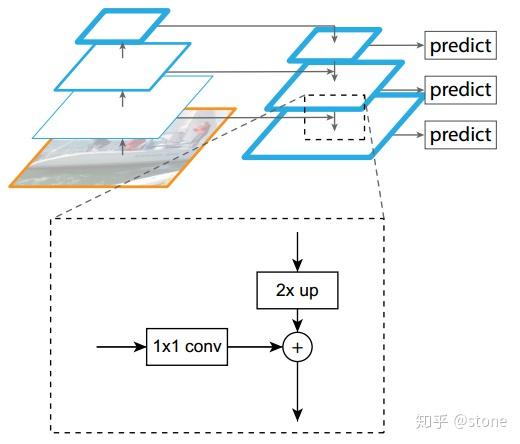
多尺度检测在目标检测中变得越来越重要,对小目标的检测尤其如此。现在主流的目标检测方法很多都用到了多尺度的方法,包括最新的yolo v3。Feature Pyramid Network (FPN)则是一种精心设计的多尺度检测方法
特征金字塔是为了多尺度检测FPN结构中包括自下而上,自上而下和横向连接三个部分,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息,在特征学习中算是一把利器了。
Mask RCNN定义多任务损失:
L=L_{cls}+L_{box}+L_{mask}
最近在做一个目标检测项目,用到了Mask RCNN。我仅仅用了50张训练照片,训练了1000步之后进行测试,发现效果好得令人称奇。就这个任务,很久之前用yolo v1训练则很难收敛。不过把它们拿来比当然不公平,但我更想说的是,mask RCNN效果真的很好。
所以这篇文章来详细地总结一下Mask RCNN。
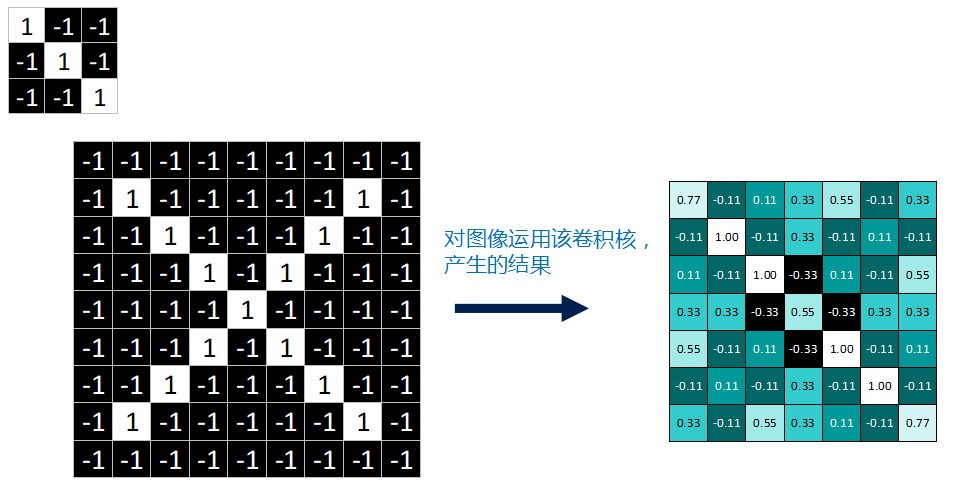
feature在CNN中也被成为卷积核(filter),一般是3X3,或者5X5的大小
^3ecb3c65卷积神经网络在本质和原理上还是和卷积运算有一定的联系的
^e3448be7好了,经过一系列卷积对应相乘,求均值运算后,我们终于把一张完整的feature map填满了。
^3775cc34非线性激活层
卷积层对原图运算多个卷积产生一组线性激活响应,而非线性激活层是对之前的结果进行一个非线性的激活响应。
指的是对卷积得到的结果再次处理.
非线性激活使用的就是非线性激活函数 ^a7676697
卷积操作后,我们得到了一张张有着不同值的feature map,尽管数据量比原图少了很多,但还是过于庞大(比较深度学习动不动就几十万张训练图片),因此接下来的池化操作就可以发挥作用了,它最大的目标就是减少数据量。
池化分为两种,Max Pooling 最大池化、Average Pooling平均池化。顾名思义,最大池化就是取最大值,平均池化就是取平均值。
^251b2749
拿最大池化举例:选择池化尺寸为2x2,因为选定一个2x2的窗口,在其内选出最大值更新进新的feature map。
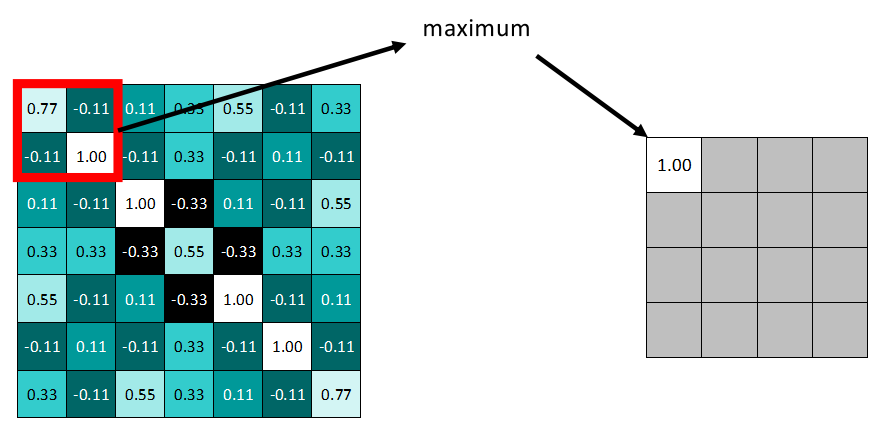
同样向右依据步长滑动窗口。
Tensors are similar to NumPy’s ndarrays, except that tensors can run on GPUs or other hardware accelerators. In fact, tensors and NumPy arrays can often share the same underlying memory, eliminating the need to copy data (see Bridge with NumPy).
Tensor与np.ndarray非常相似 ^baaea2f8Tensors can be created from NumPy arrays (and vice versa
^60681efcBridge with NumPy
Tensors on the CPU and NumPy arrays can share their underlying memory locations, and changing one will change the other.
t = torch.ones(5)
print(f”t: {t}”)
n = t.numpy()
print(f”n: {n}”)
t: tensor([1., 1., 1., 1., 1.])
n: [1. 1. 1. 1. 1.]
A change in the tensor reflects in the NumPy array.
torch.utils.data.DataLoaderandtorch.utils.data.Dataset.Datasetstores the samples and their corresponding labels, andDataLoaderwraps an iterable around theDataset.
Dataset 用于定义和存储数据及标签,而 DataLoader 则将 Dataset 包装成一个可迭代对象,方便进行批量数据处理和多线程数据加载。 ^40d33fcfPyTorch offers domain-specific libraries such as TorchText,TorchVision, and TorchAudio
^03b16e1aTo define a neural network in PyTorch, we create a class that inherits from nn.Module. We define the layers of the network in the
__init__function and specify how data will pass through the network in theforwardfunction. To accelerate operations in the neural network, we move it to the GPU or MPS if available.
Using cuda device
NeuralNetwork(
(flatten): Flatten(startdim=1, end_dim=-1)
(linear_relu_stack): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU()
(4): Linear(in_features=512, out_features=10, bias=True)
)
)
继承自nn.Module的类来定义一个新的神经网络_ ^60509680
Note
Click hereto download the full example code
Learn the Basics ||Quickstart ||Tensors ||Datasets & DataLoaders ||Transforms ||Build Model ||Autograd ||Optimization ||Save & Load Model
斯拉夫人,在宗教进入他们文明史之前,他们记录的东西很少,俄罗斯人的历史是以《往年纪事》为开端的,这本书诞生于1377年,记录的事情的起点是在859年,而859年都是唐宣宗时代了,属于唐末民变的时代的开端。
^abefa6cf类似的故事不光是在俄罗斯,波兰也有,过去波兰不是搞过一个动画片么?
下面这个。
所以为什么西方人注重宗教,中国人看都不看、
简单:宗教对于西方人来说,是其历史,文明史的开端,无比的重要。
对于中国来说,那尽想到什么鸦片战争,八国联军……
^5e22f16a
为什么要辩经?因为咱们这是过渡期,必须知道经文,解构经文。
当然最大的原因还是:好玩。
对于欧洲来说,很多国家的文明史就是宗教史,举个例子。
==斯拉夫人,在宗教进入他们文明史之前,他们记录的东西很少,俄罗斯人的历史是以《往年纪事》为开端的,这本书诞生于1377年,记录的事情的起点是在859年,而859年都是唐宣宗时代了,属于唐末民变的时代的开端。==
而这本书里面有一大坨的宗教概念,什么诺亚的故事,诺亚儿子的故事等等。
速度: 经典的目标检测算法使用滑动窗法依次判断所有可能的区域。本文则(采用Selective Search方法)预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上(采用CNN)提取特征,进行判断。
相较于传统算法,通过滑动窗口寻找,rcnn使用了selective search,再在可能的区域上进行CNN提取特征RCNN算法分为4个步骤
Selective Search 主要思想:
其中合并规则如下: 优先合并以下四种区域:

每年咱们国庆的时候,他们街道都会挂上中国的国旗,当年我们的《战狼2》、《红海行动》、《流浪地球》、《我和我的祖国》电影上映时,塞尔维亚街头都会出现大幅电影海报。
同为遭受过苦难、压迫的第三世界国家,我们和塞尔维亚人民之间,是有共同感情的。
^a09c631d
塞尔维亚、克罗地亚、黑山、斯洛文尼亚、波黑、马其顿……他们曾经都有一个祖国,叫做“南斯拉夫”——南斯拉夫社会主义联邦共和国。
曾经,他们是社会主义兄弟,他们还是欧洲唯一一个不靠苏联红军、不靠欧美盟军、而是靠自己的革命力量战胜纳粹,赢得民族解放的伟大国家。
^f6563399
他们甚至也有着自己的“长征”。
在前两次“围剿”铁托和游击队失败之后,德意法西斯与伪军又发起第三次“围剿”。来势十分凶猛,法西斯军队不仅占领革命根据地,而且大肆屠杀无辜百姓,制造广泛的“无人区”,隔绝游击队与人民的联系。南反法西斯斗争进入最困难的时期。南共中央决定突破敌人封锁线进行战略转移,这样就开始了堪称欧洲的“长征”。
^b1c8e8e7
南斯拉夫长征甚至也有自己的“遵义会议”,在战斗最惨烈的苏杰斯卡战役后(苏捷斯卡战役很像“湘江血战”),游击队司令部在一个小磨坊召开会议,这就是南斯拉夫的遵义会议,会议上铁托决定向敌人力量薄弱的波斯尼亚地区转移,在那里建立新的根据地。
^3092b473南斯拉夫人民曾经也有一个统一、富强、独立的大国梦啊,只可惜,在内外敌人的联手破坏、绞杀下破灭了,国家被拆散,四分五裂,人民被轰炸被屠杀,民选的领导人被抓捕,被国际法庭审判,死得不明不白。
^612fd013分裂的背后,往往都是国际强权的阴谋和阳谋。那些顶级的掠食者,不愿意另一个统一的、强大的挑战者出现,不愿意他们成长起来,所以,他们花钱策反,动用媒体和舆论、文化入侵,鼓动分裂和内斗,鼓吹独立和自由,甚至直接武装干涉,最终把潜在的对手一一肢解,然后掠夺他们的人才和资源。
工业化本身就是极大偶然,资本主义是后世追加的,如果没有工业化也不存在资本主义一说,只有封建主义,工业化不是人类发展的必然方向,只是一个偶发事件。
^a0732981这个世界不可能全部进入工业化,只有部分国家可以工业化,因为工业化需要市场,资源供给和技术,而资本的利润需要收割,工业化国家的矛盾需要外部化,这个不是制度、意识形态或者道德问题,这个是工业化的本质问题,扩大生产必然带来市场扩张需求,压低资源价格需求和技术升级需求,最后只能走入帝国争霸,大多数人口和国家只能是其它工业化片区的外围。
残酷的世界真相 ^21631b40新自由主义后形成的后发国家港口型工业区,那不是这些后发国家的,这个道理这么难懂吗?搞工业和搞工业化不是一个概念,工业化是社会革命为前提,工业谁都能搞,两码事,这些外资控制的工业他的脐带在工业化国家,不在这些后发国家
^1cafc216当然先发展的工业化国家倒是有掉沟里的风险的,一旦几项要素不匹配了,或者缺了,那就没办法继续玩了,工业化没有真正的完成时,只有进行时,一旦滚不起来,停了就死。
只有死亡才会落地的鸟 ^e52e2cf8
简单说吧,还是有朋友纠结后发国家的工业化问题或者叫追赶问题
第一,==工业化本身就是极大偶然,资本主义是后世追加的,如果没有工业化也不存在资本主义一说,只有封建主义,工业化不是人类发展的必然方向,只是一个偶发事件。==
第二,==这个世界不可能全部进入工业化,只有部分国家可以工业化,因为工业化需要市场,资源供给和技术,而资本的利润需要收割,工业化国家的矛盾需要外部化,这个不是制度、意识形态或者道德问题,这个是工业化的本质问题,扩大生产必然带来市场扩张需求,压低资源价格需求和技术升级需求,最后只能走入帝国争霸,大多数人口和国家只能是其它工业化片区的外围。==
第三,==新自由主义后形成的后发国家港口型工业区,那不是这些后发国家的,这个道理这么难懂吗?搞工业和搞工业化不是一个概念,工业化是社会革命为前提,工业谁都能搞,两码事,这些外资控制的工业他的脐带在工业化国家,不在这些后发国家==,严格意义上说,只有中国透过地缘博弈和高维组织度完成了自主工业化,韩国算半个,即使如此我们在过去某两段时间内也有很强的外资控制属性,当然因为本身工业体系和主权的完整有惊无险的走过去了。
第四,==当然先发展的工业化国家倒是有掉沟里的风险的,一旦几项要素不匹配了,或者缺了,那就没办法继续玩了,工业化没有真正的完成时,只有进行时,一旦滚不起来,停了就死。==